
本記事では、音声・静止画・動画といった大容量データを効率よく扱うための「圧縮」と「伸長」の基本的な考え方、圧縮率や可逆圧縮・非可逆圧縮といった評価指標や種類、さらにランレングス法・ハフマン法といった代表的な圧縮アルゴリズム、実務でよく使われるZIP形式の特徴を分かりやすく解説します。
1. 圧縮と伸長の役割をつかむ

この章では、そもそもなぜ情報を圧縮するのか、圧縮と伸長がどのような場面で役立つのかを整理します。データ保存やネットワーク通信と結び付けてイメージすると理解しやすくなります。
圧縮と伸長のイメージ
圧縮とは、元のデータの内容は変えずに、できるだけ少ない量のビット列で表現し直すことです。例えると、かさばる荷物を小さなスーツケースにきれいに詰め直す作業に相当します。逆に、圧縮されたデータから元のデータを取り出す処理を伸長(展開・解凍)と呼びます。
音声データや静止画データ、動画データは、そのまま保存すると非常に大きな容量になります。そこで圧縮を行うことで、同じ内容をより小さなファイルサイズで扱えるようになります。伸長の処理は、保存されたデータを再生・表示するときに必ず行われており、利用者は意識しないうちに圧縮と伸長の仕組みの恩恵を受けています。
圧縮の目的と圧縮率
圧縮の主な目的は二つあります。一つは、ハードディスクやSSDなどの記憶装置を節約することです。データ量が半分になれば、同じ容量のストレージに2倍のファイルを保存できるようになります。もう一つは、ネットワークの負荷を軽減することです。ファイルサイズが小さくなれば、同じ回線速度でも短い時間で送受信が可能になり、Webサイトの表示や動画視聴の待ち時間を減らせます。
圧縮の効果を数量的に表す指標が「圧縮率」です。一般的には「圧縮後のサイズ ÷ 圧縮前のサイズ」で表し、数値が小さいほど効率良く圧縮できていることになります。たとえば、100MBのデータが20MBになった場合、圧縮率は0.2で、元の20%のサイズになったという意味です。逆に「5倍に圧縮した」といった言い方をするときは、「圧縮前のサイズ ÷ 圧縮後のサイズ」を指していることもあるため、コンテキストに注意して読み取る必要があります。
可逆圧縮
可逆圧縮とは、圧縮前と伸長後のデータが完全に一致するタイプの圧縮方式を指します。つまり、一度圧縮しても、伸長すれば1ビットも違わない元のデータを取り戻せる方式です。文章ファイルやプログラム、表計算データなど、内容が少しでも変わると困るデータには、基本的に可逆圧縮が使われます。
可逆圧縮では、データの中に含まれる「繰り返し」や「出やすいパターン」をうまく利用して、無駄なく符号化していきます。ただし、情報を一切捨てないため、圧縮できる量には限界があります。画像や音声などのマルチメディアデータを、可逆圧縮だけで極端に小さくすることは難しい、という点も合わせて覚えておくとよいでしょう。
非可逆圧縮
非可逆圧縮は、圧縮の過程で一部の情報を捨ててしまう方式です。そのため、一度圧縮したデータを伸長しても、元のデータを完全に復元することはできません。ただし、人間が見たり聞いたりしても分かりにくい部分を中心に削ることで、画質・音質の劣化をなるべく感じさせないよう工夫されています。
代表例として、JPEG画像やMP3音声、MPEG系の動画などが挙げられます。これらは静止画データや音声データ、動画データのデータ量を大きく削減できるため、ネットワークを通した配信や長時間の保存に向いています。非可逆圧縮は「完全には元に戻らない」という点で可逆圧縮と性質が異なりますが、実用上は十分な品質が得られるため、マルチメディア分野では広く利用されています。
2. 代表的な圧縮アルゴリズム
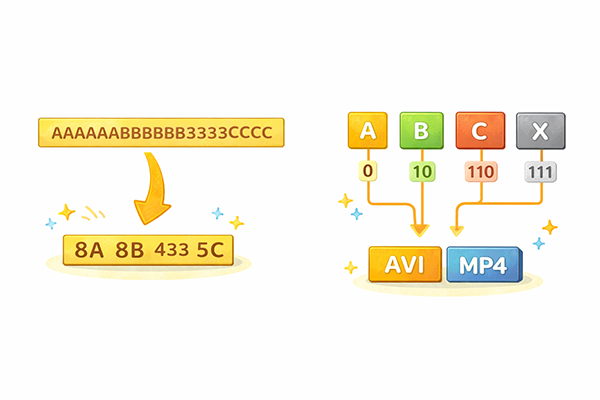
この章では、可逆圧縮でよく使われる典型的なアルゴリズムとして、ランレングス法とハフマン法を取り上げます。仕組みをざっくり理解しておくことで、多くの圧縮方式の考え方が見えやすくなります。
ランレングス法
ランレングス法は、同じデータが連続して並んでいる部分を圧縮するシンプルな方式です。「ラン(run)」とは同じ値が続く列のことで、その長さ(レングス)を記録することからこの名前が付いています。たとえば、画像のある行に「白・白・白・白・黒・黒」というピクセルが並んでいる場合、「白4個、黒2個」といった形で表現し直すイメージです。
この方式は、単色の領域が大きい画像や、同じ文字が連続しやすいデータに対して特に効果を発揮します。一方で、すべてのデータに向いているわけではなく、色や値が頻繁に変わる場合には、かえってデータが増えてしまうこともあります。そのため、ランレングス法単体で使われるだけでなく、他の方式と組み合わせて利用されることも多くあります。仕組みが分かりやすいので、圧縮の入門的な例として押さえておくとよい方式です。
ハフマン法
ハフマン法は、データの中で出現頻度の高い記号には短いビット列を、出現頻度の低い記号には長いビット列を割り当てることで、全体として必要なビット数を減らす方式です。新聞記事で、よく出てくる文字を一文字で、まれにしか出ない語を長い略号で表すと、文章全体の長さを短くできる、というイメージに近い考え方です。
ハフマン法では、記号ごとの出現頻度に基づいて「ハフマン木」と呼ばれる二分木を作り、その枝の通り道を0と1で表現します。よく出る記号ほど根に近い位置に配置されるため、割り当てられるビット列は短くなります。逆に、めったに出ない記号は木の深い位置に置かれ、長いビット列になります。こうすることで、データ全体を効率良く符号化できるのです。多くの圧縮形式の内部で、ハフマン法またはそれに類似した手法が利用されているため、頻度に応じて符号長を変えるという発想を覚えておくことが重要です。
3. 実務でよく使う圧縮形式

この章では、日常的に触れることの多いZIP形式を例に、圧縮がどのように実務に活用されているのかを説明します。複数のファイルやフォルダをまとめて扱える点が、単なる圧縮方式との違いです。
ZIP
ZIPは、複数のファイルやフォルダを一つのファイルにまとめ、その中身を圧縮して保存できる形式です。WindowsやmacOSなど主要なOSが標準で対応しているため、特別なソフトを用意しなくても扱えることが多く、ファイルのやり取りに広く利用されています。
ZIPファイルの中では、可逆圧縮のアルゴリズム(LZ系の方式とハフマン法などの組み合わせ)が用いられ、テキストや文書、表計算、画像などさまざまな種類のファイルをまとめて圧縮します。これにより、メール添付で送れるサイズに収めたり、バックアップの保存容量を節約したりすることができます。また、一つのZIPファイルにまとめることで、フォルダ構造ごと簡単にコピー・移動できる点も便利です。
マルチメディアデータの圧縮活用
音声データ、静止画データ、動画データのようなマルチメディアは、単にZIPでまとめて圧縮するだけでなく、データの種類ごとに最適化された専用の圧縮方式が利用されることが多くあります。画像であればJPEGやPNG、音声であればMP3やAAC、動画であればMPEGやH.264/H.265といった方式が該当します。
これらの方式は、データの中身の特徴を詳しく分析して圧縮しているため、汎用的なZIP圧縮よりも高い圧縮効率を得られる場合が多くあります。現実には、まず音声・画像・動画をそれぞれの専用方式で圧縮し、そのうえでこれらのファイルをZIPなどでまとめて扱う、といった使い方が一般的です。用途に応じて「どの段階で、どの方式の圧縮が行われているか」を意識すると、実務でのデータ管理が理解しやすくなります。
まとめ
情報の圧縮と伸長は、大容量のデータを現実的なサイズで保存・送受信するために欠かせない仕組みです。圧縮によってファイルサイズを小さくすることで、ストレージの利用効率を高めるだけでなく、ネットワークの負荷を減らし、ダウンロード時間や表示時間を短縮できます。伸長は、圧縮されたデータを元の形に戻すための処理であり、利用者がファイルを開いたり、音声や動画を再生したりするときに裏側で必ず行われています。
圧縮方式には、元のデータを完全に復元できる可逆圧縮と、ある程度の情報を削ってしまう非可逆圧縮があります。文章やプログラムのように1ビットの違いも許されないデータには可逆圧縮が、音声・画像・動画のように人間の感覚で違いが分かりにくい部分を削ってもよいデータには非可逆圧縮が選ばれます。また、ランレングス法やハフマン法のようなアルゴリズムは、多くの圧縮方式の土台となっており、「繰り返し」や「出現頻度の違い」といったデータの特徴を利用して効率化を図っていることが分かります。
実務では、ZIPファイルを使って複数のファイルをまとめて圧縮したり、マルチメディア専用の圧縮形式を組み合わせてデータを扱ったりする場面が多くあります。情報の圧縮と伸長に関する基本的な考え方と用語を押さえておくことで、容量オーバーの原因を理解したり、最適な保存方法や送信方法を選んだりできるようになります。日常的に扱うデータの裏側で、どのような圧縮が働いているのかを意識しながら、知識を活用していくことが大切です。

コメント