
本記事では、業務で扱う大量のデータをどのように整理・共有・活用するかという観点から、データベースの目的と特徴、そしてデータモデルの考え方をまとめます。単なる「データの置き場」ではなく、なぜデータベースという仕組みが必要なのか、どんな性質を持っているのか、さらにはデータをどのような構造で表現するのかを理解することで、ITパスポート試験で問われるデータベースの基本イメージをつかむことができます。
1. データベースが求められる理由

この章では、そもそもなぜデータベースが必要なのか、どのような目的で導入されるのかを整理します。データを一か所に集めておくことの意味や、多くの人が同じデータを共有しながら業務を行うメリットをイメージできるようにしておくことが大切です。
データの一元管理
データベースの大きな目的の一つが「データの一元管理」です。部署ごと、担当者ごとにバラバラにファイルを作っていると、どれが最新なのか分からなくなったり、同じデータが何種類も存在したりして混乱のもとになります。データベースでは、取引先情報や商品情報などを一つの場所にまとめて保存し、「ここを見れば正しい情報が分かる」という状態を作ります。
一元管理されていると、データを探す時間が減るだけでなく、更新の手間も減ります。例えば住所が変わった取引先があった場合でも、データベース上の1か所を直せば済みます。もし部署ごとに別々のファイルを持っていれば、営業部・経理部・物流部と、すべて更新しなければならず、更新漏れが起きるリスクが高くなります。
共有と同時利用
データベースは、多くの利用者が同じデータを共有するための仕組みとして使われます。営業担当が入力した受注データを、すぐに在庫管理担当が確認し、倉庫側が出荷処理に進める、といった流れを支えているのがデータベースです。これにより、部署間で情報を受け渡しするための電話やメールが減り、業務のスピードが上がります。
さらに、データベースは複数の人が同時に使うことを前提に設計されています。誰かがデータを更新している間に、別の人が間違って古い状態で上書きしてしまうと困りますが、データベースでは「同時利用の制御」を行うことで、データが矛盾した状態にならないように工夫されています。
データ活用と意思決定
データベースは、単に情報を保存するだけでなく、蓄積されたデータを分析して経営判断に活かすためにも使われます。売上データやアクセスログを集めておけば、「どの商品がどの地域でよく売れているのか」「どの時間帯にアクセスが集中しているのか」といった傾向を見つけることができます。
このように、データベースは「将来の意思決定のための資産」という位置づけでもあります。日々の業務で発生するデータをきちんと蓄積しておくことで、後からさまざまな角度で分析できるようになり、業務改善や新サービスの企画などにも役立ちます。
2. データベースの主な特徴

この章では、データベースが他の単純なファイル保存と比べてどのような特徴を持っているのかを整理します。特に、データの独立性、冗長性の削減と整合性、信頼性と可用性といったキーワードを押さえておくと、試験問題の文章を読み解きやすくなります。
データの独立性
データベースの特徴としてよく挙げられるのが「データの独立性」です。これは、データの持ち方(データ構造)と、そのデータを利用するアプリケーションをできるだけ分離しておくという考え方です。例えば、顧客情報の項目を一つ増やす場合でも、データベース側の定義を変更するだけで、アプリケーションの変更は最小限で済むように設計します。
この独立性が高いほど、業務の変更やシステムの拡張に柔軟に対応できます。もしアプリケーションとデータが密接に結び付いていると、項目を増やすたびにプログラムを大幅に書き直さなければならず、変更コストが大きくなってしまいます。データベースは、このような変更に強い仕組みを提供することで、長期的なシステム運用を支えています。
冗長性の削減と整合性
「冗長性」とは、同じ内容のデータが何度も重複して保存されている状態を指します。データベースでは、同じ情報をできるだけ一か所にまとめて持つように設計することで、冗長性を減らすことを目指します。例えば、顧客マスタと注文データを分け、顧客名や住所は顧客マスタだけに保存し、注文側には顧客を識別する番号だけを記録する、といった構造が代表的です。
冗長性を減らすと、データの「整合性」を保ちやすくなります。整合性とは、データ同士に矛盾がない状態のことです。もし顧客名を複数のファイルにバラバラに持っていた場合、どこか一つを修正し忘れると、顧客名が場所によって違うといった矛盾が生じます。データベースでは、更新すべき場所を最小限に抑える設計や、制約によるチェックを通じて、整合性を維持する仕組みを備えています。
信頼性と可用性
業務で使うデータは、消えてしまったり使えなくなったりすると大きな損害につながります。そのため、データベースには「信頼性」と「可用性」が求められます。信頼性とは、データが壊れたり失われたりしにくいこと、可用性とは、必要なときにきちんと利用できることを意味します。
具体的な方法として、トランザクション管理による途中失敗時のロールバック、定期的なバックアップ、障害時に備えた待機系サーバの用意などがあります。利用者から見ると、これらの仕組みは目に見えませんが、裏側でデータベース管理システム(DBMS)が動作することで、日々の業務を安心して続けられる環境が実現されています。
3. データモデルの考え方
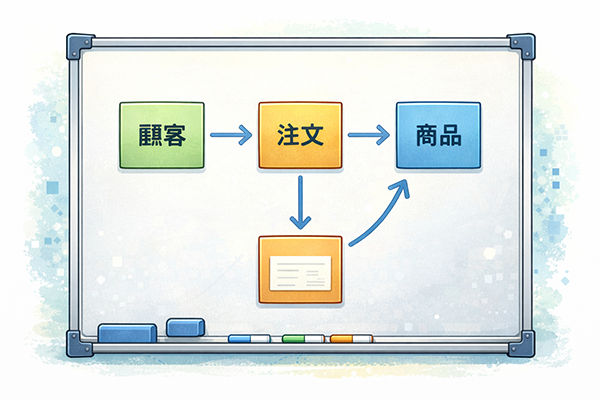
この章では、データをどのような形で表現するかという「データモデル」の考え方を取り上げます。データモデルを理解しておくと、なぜ表形式で表現したり、なぜテーブル同士をキーで結び付けたりするのかが分かりやすくなります。
概念モデルと論理モデル
データモデルを考えるときは、まず「どんな情報同士がどう関係しているか」という概念レベルの整理から始めます。例えば、顧客と注文は「顧客が注文する」という関係で結び付き、注文と商品は「注文に商品が含まれる」という関係になります。このような実世界の構造を表したものが概念モデルです。
その後、概念モデルを実際のデータベースで扱える形に落とし込んだものが論理モデルです。テーブルの名前や項目名、主キーとなる項目を決めていき、どのテーブルがどのテーブルとどのようなキーでつながるかを定義します。論理モデルの段階でしっかり設計しておくと、データの重複や矛盾を防ぎやすくなり、後からの拡張もしやすくなります。
リレーショナルデータモデル
ITパスポート試験で主に扱われるのは「リレーショナルデータモデル」です。これは、データを「表(テーブル)」の形で扱い、行と列の組み合わせで1件1件のデータを表現するという方式です。例えば、顧客テーブルには「顧客ID」「氏名」「住所」などの列があり、1行が一人の顧客に対応します。
リレーショナルデータモデルのポイントは、表同士の「関係(リレーション)」をキーで表現することです。顧客テーブルと注文テーブルを、顧客IDという共通の項目で結び付ければ、「どの顧客がどんな注文をしたか」を簡単に取り出せます。こうした関係をうまく設計することで、複雑な情報を無理なく整理し、必要なデータを柔軟に取り出すことが可能になります。
主キーと外部キーの役割
リレーショナルデータモデルでは、「主キー」と「外部キー」が重要な役割を果たします。主キーは、テーブルの中で1行を一意に識別するための項目です。顧客IDや商品コードなどが代表例で、同じ値が重複しないように管理されます。主キーがあることで、「この行のデータはこの顧客」という対応づけがはっきりします。
一方、外部キーは、別のテーブルの主キーを参照する項目です。例えば、注文テーブルにある顧客IDは、顧客テーブルの主キーである顧客IDを参照する外部キーとなります。外部キーの制約を設けることで、「存在しない顧客IDを注文テーブルに登録しない」といったルールを自動的に守ることができます。これにより、テーブル間の関係が崩れず、データの整合性が維持されます。
まとめ
データベースを振り返ると、出発点となるのは「データの一元管理と共有」を実現するための仕組みだという点でした。バラバラに管理されていた情報を一か所に集め、多くの人が同じ情報を同時に使えるようにすることで、業務の効率と正確さを高めます。また、蓄積されたデータを分析することで、将来の意思決定に役立てるという役割も担っています。
あわせて押さえておきたいのが、データベースが備えている「データの独立性」「冗長性の削減と整合性」「信頼性と可用性」といった特徴です。これらは、単なるファイル保存との違いを理解するためのキーワードでした。データベース管理システムがこれらの特徴を実現しているおかげで、利用者は安心してデータを扱うことができます。
さらに見方を広げると、背景にはデータモデルの考え方があります。実世界の構造を整理する概念モデルと、テーブルやキーを定める論理モデルがあり、特にリレーショナルデータモデルでは主キーと外部キーを使ってテーブル同士の関係を表現します。これらの考え方を押さえておけば、テーブル構造の図やSQLの問題を目にしたときでも、背景にある仕組みをイメージしながら理解できるようになります。

コメント