
本記事では、システムの信頼性をどのように評価し、どのような仕組みで高めていくのかという考え方を整理しながら、稼働率・故障率・MTBF・MTTRといった指標から、デュアルシステムやフェールセーフなどの代表的な信頼性設計の用語までを、一つひとつ丁寧に解説します。
1. 信頼性を測る指標と稼働率
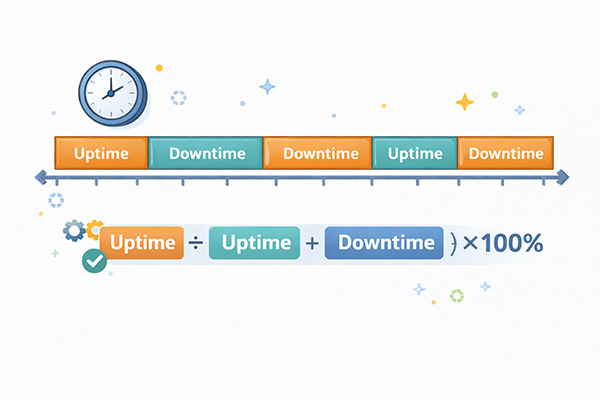
この章では、システムの信頼性を数値として捉えるための基本的な指標を扱います。感覚的な「落ちやすい」「安定している」という評価を、客観的な数値に置き換えることで、改善策の検討やシステム間の比較がしやすくなります。
稼働率
稼働率は、システムがどれだけの時間正常に動いていたかを示す指標です。一般的には、「正常に稼働していた時間」を「観測した全体の時間」で割って求めます。24時間のうち23時間動いて1時間止まっていたシステムなら、稼働率は約95.8%となります。業務にとって重要なシステムほど、高い稼働率が求められます。
稼働率は、利用者が体感する「止まりにくさ」に近い指標です。そのため、サービスレベルを決める際に「稼働率99.9%を目指す」といった目標が設定されることがあります。稼働率が高いということは、単に故障が少ないだけでなく、障害が起きたときにも短時間で復旧できていることを意味します。この点は、後述するMTBFやMTTRと密接に関係してきます。
故障率
故障率は、ある一定時間あたりどれくらいの頻度で故障が発生するかを表す指標です。たとえば、100時間に1回故障するシステムであれば、「100時間に1件」という故障率で表現できます。故障率が低いほど、長時間安定して動くシステムだといえます。
故障率は、特にハードウェア機器の信頼性を評価するときによく使われます。設計段階では、部品ごとの故障率を積み上げて、システム全体の故障しやすさを見積もることがあります。また、実際の運用データから故障率を算出すれば、「最近故障頻度が増えてきているので、更新時期を早めよう」といった判断にも役立ちます。
MTBF(平均故障間動作時間)
MTBF(Mean Time Between Failures:平均故障間動作時間)は、「故障と故障の間にどれくらいの時間、正常に動いていたか」の平均値を表す指標です。たとえば、1000時間運転して2回故障した場合、MTBFは約500時間となります。MTBFが長いほど、1回の故障から次の故障までの間隔が長い、信頼性の高いシステムであると判断できます。
MTBFは、故障率と逆の関係にあると考えることができます。故障率が低い機器ほど、MTBFは長くなります。システムの稼働率を求める際には、MTBFが大きな役割を果たします。後述のMTTRと合わせて、「MTBFが長く、MTTRが短いほど、稼働率が高くなる」という関係を押さえておくと、問題文を読み解きやすくなります。
MTTR(平均修復時間)
MTTR(Mean Time To Repair:平均修復時間)は、故障が発生してから修復が完了するまでにかかる時間の平均値を表す指標です。たとえば、3回の故障で、それぞれ復旧に1時間・2時間・4時間かかった場合、MTTRは平均で約2.3時間となります。MTTRが短いほど、障害発生時にすばやく復旧できるシステムだといえます。
MTTRには、単に機器を直す時間だけでなく、障害の検知や原因調査、部品交換、システムの再起動、動作確認などにかかる時間も含まれます。そのため、MTTRを短くするには、運用手順の整備や監視の自動化、予備部品の確保など、さまざまな取り組みが必要です。MTBFとMTTRを組み合わせると、稼働率は「MTBF ÷(MTBF+MTTR)」という形で表せるため、この2つの指標はセットで押さえておくと理解が深まります。
稼働率向上策の検討
稼働率向上策の検討では、先ほどの指標を使いながら「どこを改善すると稼働率が上がるのか」を考えます。稼働率は大まかに、「故障しにくくする(MTBFを伸ばす)」か「故障してもすぐ直す(MTTRを縮める)」か、あるいはその両方を行うことで高めることができます。たとえば、より信頼性の高い機器に入れ替えたり、部品寿命に余裕を持たせた設計にしたりするのは、MTBFを伸ばすための取り組みです。
一方、運用面では、故障時にすぐ対応できる体制を整えたり、予備機を用意したり、復旧手順をマニュアル化して訓練したりすることで、MTTRを短くできます。さらに、冗長構成を導入して、故障しても実質的なサービス停止にならないようにする方法もあります。このように、稼働率向上策はハードウェア・ソフトウェア・運用のすべての面から検討する必要があり、次章で扱う信頼性設計とも密接に関係しています。
2. 冗長構成による信頼性設計

この章では、機器やシステムを複数用意しておく「冗長構成」によって、故障が起きてもサービスを継続しやすくする設計を取り上げます。前章の指標でいうと、実質的にMTTRを限りなくゼロに近づける、あるいは故障の影響を外から見えなくするための工夫と捉えることができます。
デュアルシステム
デュアルシステムは、同じ機能を持つ2系統のシステムを同時に動かし、処理結果を照合しながら運用する構成です。2つの系統が並行して同じ処理を行い、結果が一致していることを確認しながらサービスを提供します。もし片方に誤動作や故障が発生すると、もう一方の正常な系統を優先し、異常系を切り離すことで処理の正しさを確保します。
この構成では、1台が故障してももう1台が動作し続けるため、サービスを止めずに運用できる確率が高まります。また、結果を照合することで誤動作を早期に検知できるため、信頼性を特に重視するシステムで採用されます。その反面、常に2系統分の機器を稼働させる必要があるため、コストや消費電力が大きくなる点がデメリットです。
デュプレックスシステム
デュプレックスシステムは、現用系(アクティブ系)と待機系(スタンバイ系)の2系統を用意し、通常は現用系だけを動かしておく方式です。現用系に故障が発生した場合に、待機系へ切り替えてサービスを継続します。普段は1系統のみが動いている点が、デュアルシステムとの大きな違いです。
この構成では、常時2系統を動かす必要がないため、デュアルシステムよりも比較的コストを抑えられます。一方で、切り替えのタイミングで一瞬サービスが止まる可能性があることや、待機系が常に最新の状態になるよう、データ同期や設定の反映を適切に行う必要があることが課題です。後述のコールドスタンバイ、ホットスタンバイは、この待機系の状態の違いを表す用語です。
コールドスタンバイ
コールドスタンバイは、待機系の機器を通常は停止した状態(電源OFFなど)で待機させ、故障時に起動して利用する方式です。普段は電源も切っておくため、消費電力や部品の劣化を抑えられるというメリットがあります。バックアップ機を「予備として倉庫に保管しておき、故障が起きたときに持ち出してくる」イメージに近い構成です。
ただし、故障発生から実際に予備機が稼働を開始するまでに、起動や設定、データ復元の時間が必要になります。そのため、コールドスタンバイは、瞬時の切り替えまでは求められないが、一定時間内に復旧できればよいというシステムに向いています。停止時間をどこまで許容できるかによって、コールドスタンバイで十分か、より高レベルの冗長化が必要かを判断することになります。
ホットスタンバイ
ホットスタンバイは、待機系の機器も常に起動した状態で待機させ、現用系と同じようにデータを同期しながら運用する方式です。現用系に障害が起きた場合には、待機系へ即座に切り替えることができるため、サービスの停止時間を非常に短く抑えられます。データベースサーバや重要な業務サーバでは、この方式が採用されることがあります。
ホットスタンバイでは、待機系もほぼ現用系と同じように動作しているため、コールドスタンバイよりもコストや運用負荷は高くなります。しかし、その分だけ可用性は大きく向上します。システムを設計するときには、「どれくらいの停止時間まで許されるのか」という要件に応じて、コールドスタンバイ・ホットスタンバイのどちらを選ぶか、あるいはさらに高度なクラスタ構成などを採用するかを検討していくことになります。
3. 故障しても安全に使うための設計
この章では、単に「止まりにくくする」だけでなく、「故障しても安全を確保する」「そもそも危険な操作をさせない」といった観点からの信頼性設計を扱います。人の命や重要な資産に関わるシステムでは、特に重要な考え方です。
フェールセーフ
フェールセーフは、故障や異常が発生したときに、安全な状態になるように設計しておく考え方です。「壊れるなら、安全側に壊れるようにしておく」とイメージすると分かりやすくなります。たとえば、踏切の遮断機が故障した場合には、上がったままではなく、下りた状態(通行止め)になるように設計されているのが代表的な例です。
システムでは、異常を検知したときに自動的に処理を停止し、誤った動作を続けないようにする仕組みなどがフェールセーフの一例です。業務システムでも、データの整合性が失われる恐れがある場合には、あえて処理を中断してロールバックすることで、誤った結果が外部に出ないようにしているケースがあります。フェールセーフは、「止まらないこと」よりも「安全であること」を優先する設計思想だと言えます。
フォールトトレラント
フォールトトレラント(フォールトトレランス)は、故障(フォールト)が発生しても、システム全体としては正常なサービスを継続できるようにする設計思想です。前章で扱ったデュアルシステムやデュプレックスシステム、スタンバイ構成などは、フォールトトレラントを実現するための具体的な構成に含まれます。
フォールトトレラントなシステムでは、部品の故障や一部機能の異常が起きても、予備系が自動的に処理を引き継ぎ、利用者から見れば影響をほとんど感じないようになっています。そのためには、故障検知の仕組みや自動切替の制御、複数系統間のデータ同期など、複雑な設計が必要です。フェールセーフが「安全に止まる」方向の思想なのに対し、フォールトトレラントは「止まらずに動き続ける」ことを重視している点が対比として押さえどころです。
フールプルーフ
フールプルーフは、「人は必ずしも完璧ではない」という前提に立ち、誤操作や勘違いが起きても事故につながらないようにする設計思想です。直訳すると「愚かさへの防御」といったイメージで、人間のミスを前提として、ミスをしにくく、しても重大な問題になりにくい仕組みを作ることを目指します。
具体例としては、向きを間違えて差し込めないコネクタや、危険な操作を行うときに確認ダイアログを表示するユーザインタフェース、鍵を抜いた状態ではエンジンがかからない仕組みなどが挙げられます。情報システムでも、削除ボタンを目立たない位置に置いたり、誤って押してもすぐに元に戻せるようにしたりすることで、フールプルーフを実現できます。フェールセーフやフォールトトレラントと組み合わせることで、「故障しても安全」「ミスをしても安全」という多重の防御を構築することが理想です。
まとめ
システムの信頼性を考えるときは、まず稼働率・故障率・MTBF・MTTRといった指標で「どれくらい壊れにくいのか」「壊れたときにどれくらいで戻せるのか」を数値として把握することが出発点になります。感覚的な「なんとなく安定している」ではなく、客観的な数値に落とし込むことで、改善の優先順位や投資効果を判断しやすくなります。
そのうえで、デュアルシステムやデュプレックスシステム、コールドスタンバイやホットスタンバイといった冗長構成を活用すれば、障害が発生してもサービスを継続しやすいシステムを実現できます。これらは、実質的に停止時間を短くし、稼働率を高めるための強力な手段です。ただし、冗長化にはコストや運用の複雑さが伴うため、どのレベルの可用性が必要かを明確にしたうえで選択することが重要です。
さらに、フェールセーフ・フォールトトレラント・フールプルーフといった設計思想を取り入れることで、「壊れたときに安全であること」「故障しても動き続けること」「人がミスしても事故にならないこと」を多面的に実現できます。システムの信頼性は、単に止まりにくさだけでなく、安全性や人間の特性も含めた総合的な概念です。用語を単独で覚えるのではなく、指標と構成・設計思想がどのようにつながっているのかを意識して整理しておくと、理解がより確かなものになります。

コメント